下面学习如何使用 vikit-learn 训练一个图像分类器。我们将使用猫狗图像数据集 OxfordIIITPet 来进行实践操作。
安装 vikit-learn 工具
我们可以使用pip工具从 github 上在线下载并安装 vikit-learn:
pip install git+https://github.com/bxt-kk/vikit-learn.git
编写训练脚本
我们需要编写一点脚本代码来训练我们的模型。
1. 引入 vikit-learn 和 pytorch 相关的包
import torch
from torch.utils.data import DataLoader
from vklearn.trainer.trainer import Trainer
from vklearn.trainer.tasks import Classification as Task
from vklearn.models.trimnetclf import TrimNetClf as Model
from vklearn.datasets.oxford_iiit_pet import OxfordIIITPet
- Trainer: 一个通用的训练器工具,用于设定训练参数和执行训练过程;
- Classification:指定分类任务相关的训练参数;
- TrimNetClf:vikit-learn 内置的分类器模型;
- OxfordIIITPet:vikit-learn 内置的数据集工具;
2. 准备训练数据
dataset_root = '/kaggle/working/OxfordIIITPet'
dataset_type = 'binary-category'
train_transforms, test_transforms = Model.get_transforms()
train_data = OxfordIIITPet(
dataset_root,
split='trainval',
target_types=dataset_type,
download=False,
transforms=train_transforms)
test_data = OxfordIIITPet(
dataset_root,
split='test',
target_types=dataset_type,
transforms=test_transforms)
首先,我们需要指定数据的存放位置dataset_root;然后,我们指定数据的类型dataset_type = 'binary-category',这表示猫狗图像的二分类数据;另外,我们将数据分割成训练集split='trainval'和测试集split='test'。
注意!如果本地目录中没有数据,那么我们需要把download设置为True以从网络上下载数据。
batch_size = 128
train_loader = DataLoader(
train_data, batch_size,
shuffle=True,
drop_last=True,
num_workers=4)
test_loader = DataLoader(
test_data, batch_size,
shuffle=False,
drop_last=True,
num_workers=4)
print(len(train_loader))
我们使用 pytorch 提供的数据加载工具DataLoader实现数据加载,这里我们设置batch_size = 128。
3. 创建模型和创建训练任务
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Model(categories=train_data.bin_classes)
task = Task(model, device)
我们使用TrimNetClf类创建了一个模型。这里,我们需要为模型指定分类类别的数量以及类别的名称,为此,我们将train_data.bin_classes的值作为模型的categories参数值。接着,我们使用模型对象model和计算装置对象device创建训练任务对象task = Task(model, device)。
4. 初始化训练器
trainer = Trainer(
task,
output='/kaggle/working/catdog-clf',
train_loader=train_loader,
test_loader=test_loader,
epochs=20,
lr=1e-3,
lrf=0.2,
show_step=50,
save_epoch=5)
trainer.initialize()
通过设置训练器参数,我们可以创建一个用于模型训练的训练器,在创建训练器对象后,需要执行trainer.initialize()方法进行初始化。
我们对该训练器进行了如下参数设定:
task:指定训练任务;output:设定训练数据输出路径,用于存储 checkpoint 和日志;train_loader:指定训练集加载器;test_loader:指定测试集加载器;epochs:设置总共训练多少轮;lr:设置学习率大小;lrf:设置学习率衰减因子;show_step:设置每隔多少步打印训练状态;save_epoch:设置每隔多少轮存储一次 checkpoint;
5. 执行训练任务
最后我们通过如下代码,开始模型训练:
trainer.fit()
当模型训练结束后,我们会在训练器输出路径同级目录下的 logs 子目录中看到训练日志:
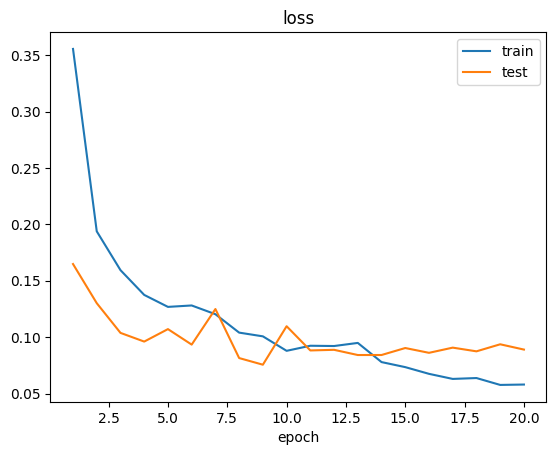
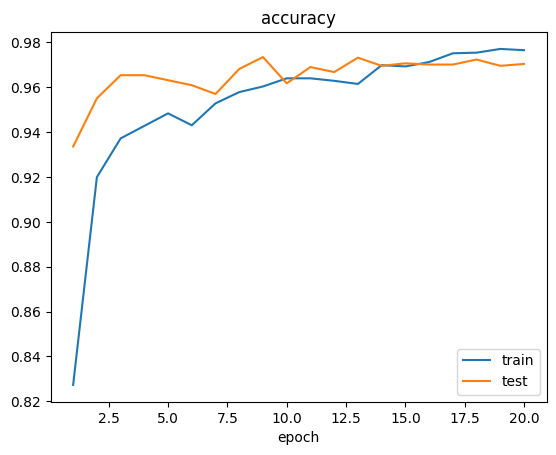
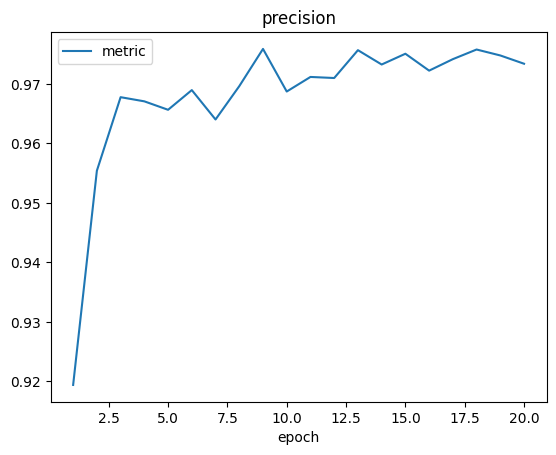
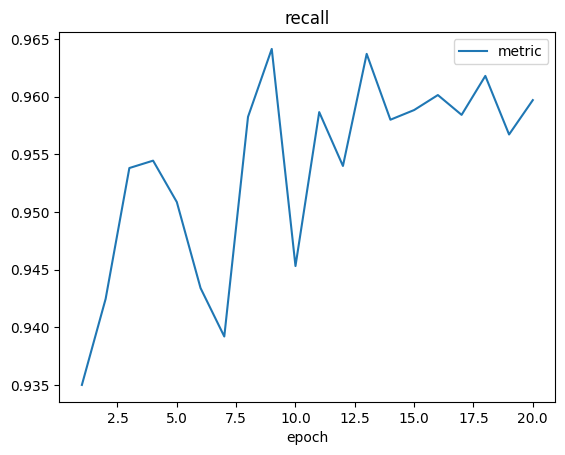
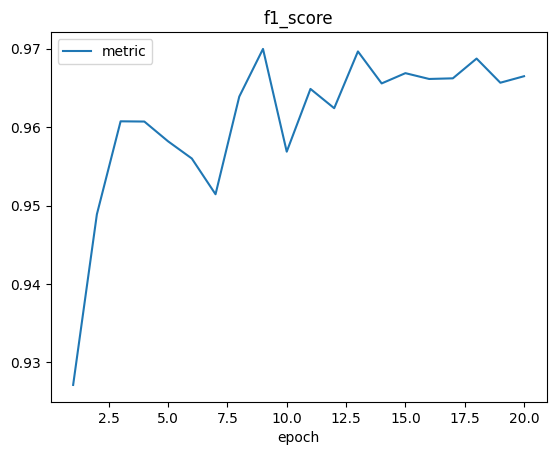
除了日志,我们还会看到如下 checkpoint 文件:
- catdog-clf-4.pt
- catdog-clf-9.pt
- catdog-clf-14.pt
- catdog-clf-19.pt
- catdog-clf-best.pt
一般来说,我们挑选best.pt结尾的进行使用,因为这是在测试集评估指标中得分最高的checkpoint。
图像分类器的使用
在完成图像分类器训练后,我们就可以使用训练好的分类器来对图像进行自动分类了。
1. 首先我们引入所需的包
import matplotlib.pyplot as plt
from PIL import Image
from vklearn.models.trimnetclf import TrimNetClf as Model
from vklearn.pipelines.classifier import Classifier as Pipeline
from vklearn.pipelines.classifier import Classifier将引入流水线工具Classifier,该工具极大简化了模型的调用。
2. 指定模型类别和模型参数文件生成分类器
pipeline = Pipeline.load_from_state(
Model, '???/catdog-clf-best.pt')
注意!记得将'???/catdog-clf-best.pt'替换为你电脑中 checkpoint 文件的真实路径。
3. 打开模型进行分类预测并可视化结果
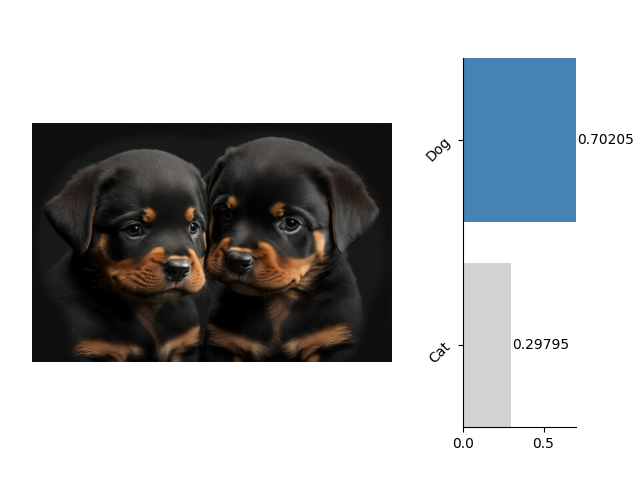
在完成之前一系列的准备工作后,我们就可以使用如下代码进行分类操作了:
img = Image.open('??your image path??')
result = pipeline(img)
fig = plt.figure()
pipeline.plot_result(img, result, fig)
plt.show()
我们使用上述代码打开了一张图像img = Image.open('??your image path??')进行分类预测result = pipeline(img),并可视化了预测结果: