最近我新开发了一个 Python 工具,给大家介绍一下:vikit-learn 是一个基于深度学习技术,使用 Python 开发的计算机视觉处理工具包。该软件包旨在提供一系列易于使用的工具,可以处理现实世界中的任务。该项目仍在积极建设和开发中,敬请期待!
目前支持的功能: 1. 图像分类; 2. 目标检测; 3. 语义分割; 4. 关键点和关节检测;
vikit-learn 的安装
依赖包
- matplotlib>=3.7.5
- torch>=2.1.2
- torchvision>=0.16.2
- torchmetrics>=1.4.0
- lightning-utilities>=0.11.2
- faster-coco-eval>=1.5.4
- pycocotools>=2.0.7
- clip @ git+https://github.com/openai/CLIP.git
- opencv-python>=4.10.0
使用 pip 工具进行在线安装
pip install git+https://github.com/bxt-kk/vikit-learn.git
vikit-learn 的使用
训练自己的模型
# Import `pytorch` and `vklearn`
import torch
from torch.utils.data import DataLoader
from vklearn.trainer.trainer import Trainer
from vklearn.trainer.tasks import Detection
from vklearn.models.trimnetdet import TrimNetDet as Model
from vklearn.datasets.oxford_iiit_pet import OxfordIIITPet
dataset_root = '/kaggle/working/OxfordIIITPet'
dataset_type = 'detection'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 16
lr = 1e-3
lrf = 0.2
# Get default transforms from TRBNetX
train_transforms, test_transforms = Model.get_transforms('cocox448')
# Create datasets
train_data = OxfordIIITPet(
dataset_root,
split='trainval',
target_types=dataset_type,
transforms=train_transforms)
test_data = OxfordIIITPet(
dataset_root,
split='trainval',
target_types=dataset_type,
transforms=test_transforms)
# Create model TrbnetX
model = Model(
categories=train_data.bin_classes,
)
# Create DataLoader
train_loader = DataLoader(
train_data, batch_size,
shuffle=True,
drop_last=True,
collate_fn=model.collate_fn,
num_workers=4)
test_loader = DataLoader(
test_data, batch_size,
shuffle=False,
drop_last=True,
collate_fn=model.collate_fn,
num_workers=4)
print(len(train_loader))
# Build object detection task
task = Detection(
model, device, metric_options={'conf_thresh': 0.05},
)
# Build a trainer by specifying the training task and setting up trainer parameters
trainer = Trainer(
task,
output='/kaggle/working/catdog',
checkpoint=None,
train_loader=train_loader,
test_loader=test_loader,
epochs=10,
lr=lr,
lrf=lrf,
show_step=50,
drop_optim=True,
drop_lr_scheduler=True,
save_epoch=5)
# Initialize the trainer, then perform training.
trainer.initialize()
trainer.fit()
训练完成后,将在 /kaggle/working/logs/ 目录中生成模型训练结果的可视化图像。
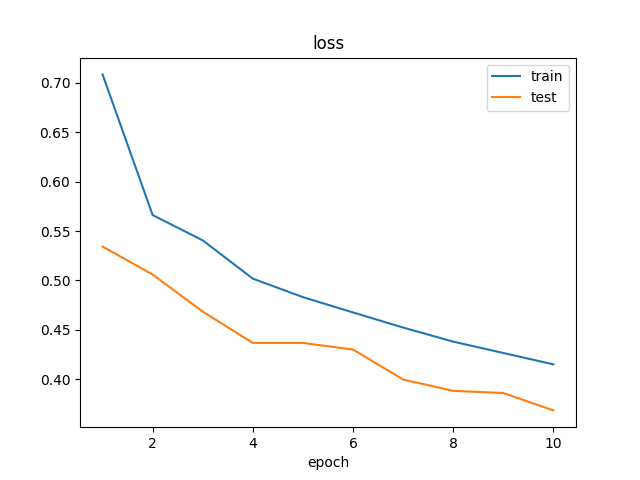
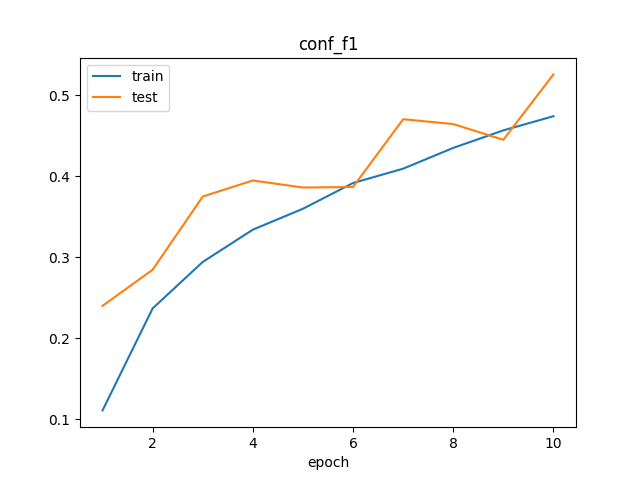
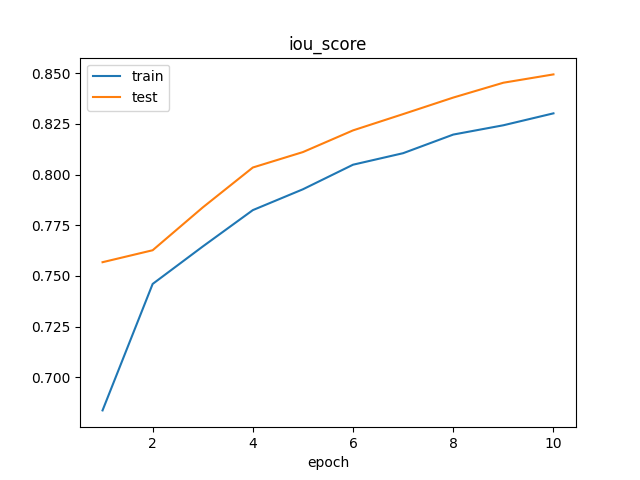
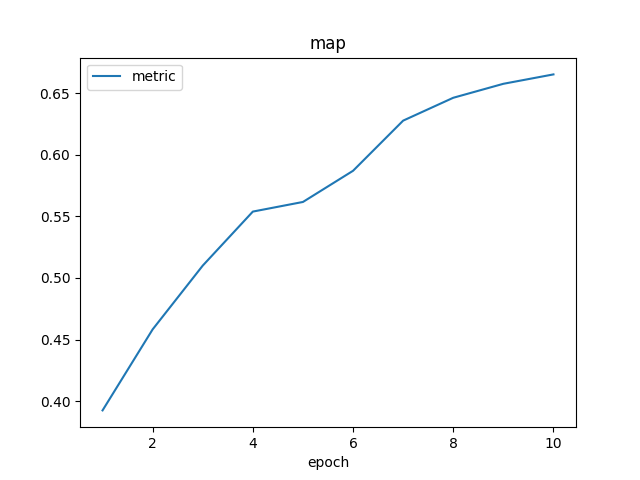
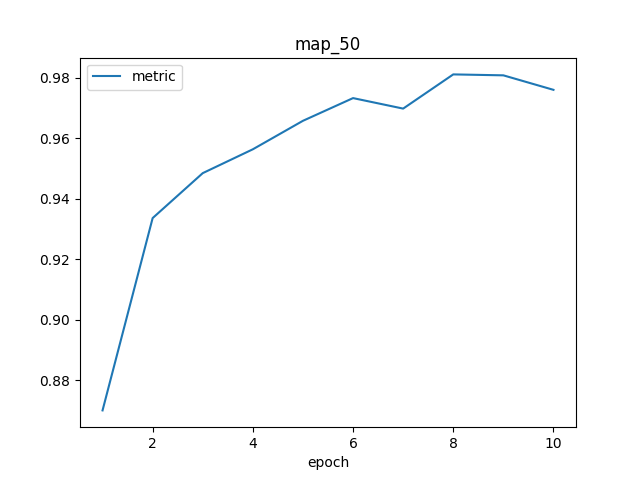
我设计的 focal-boost 损失函数,使得模型能够成功地训练于正样本比例极低的任务。
使用训练好的模型
我们可以通过以下方式调用训练好的目标检测模型:
# Import `vklearn`
from vklearn.models.trimnetdet import TrimNetDet as Model
from vklearn.pipelines.detector import Detector as Pipeline
pipeline = Pipeline.load_from_state(Model, '/kaggle/working/catdog-best.pt')
import matplotlib.pyplot as plt
from PIL import Image
img = Image.open('??YOUR IMAGE PATH??')
# Detect and display results
objs = pipeline(img, align_size=448)
print(len(objs), objs)
fig = plt.figure()
pipeline.plot_result(img, objs, fig)
plt.show()
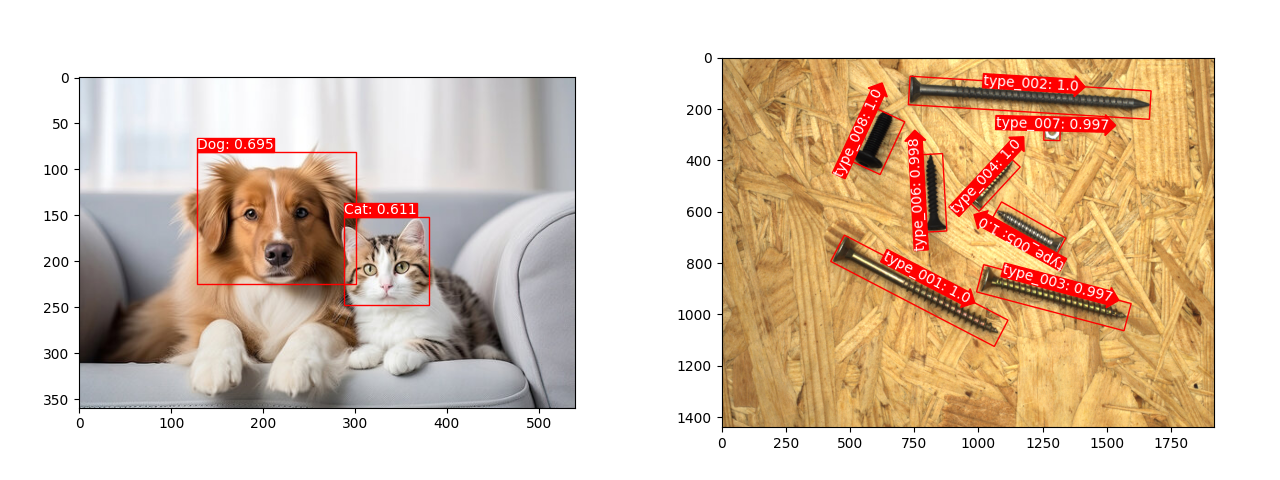
这里是一些示例:

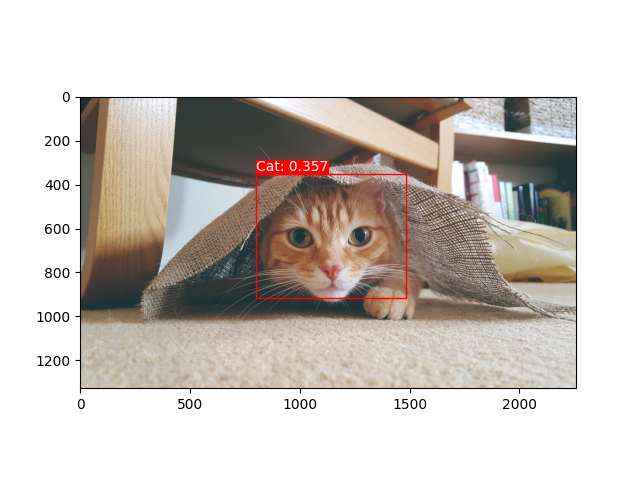




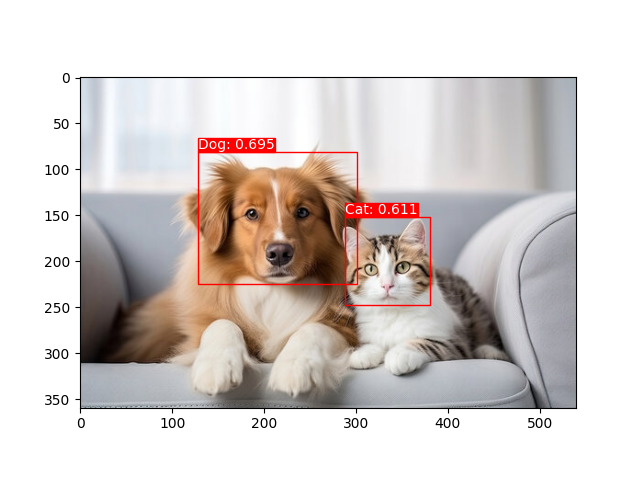
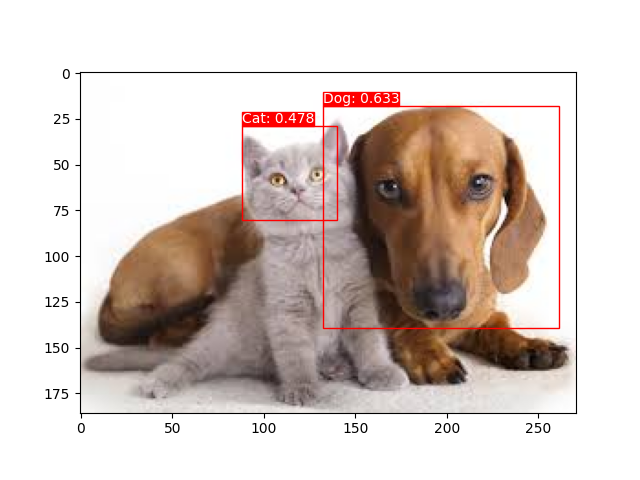
这里是一些关于图像分类的示例:
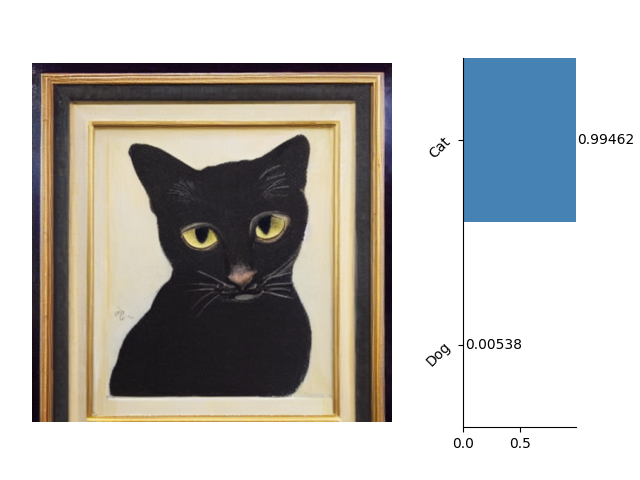
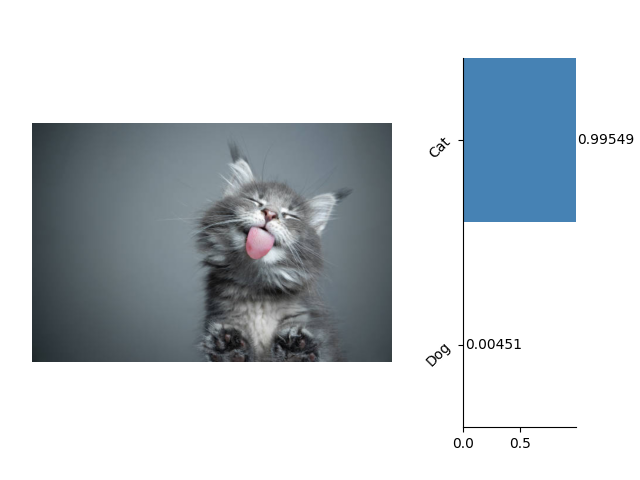

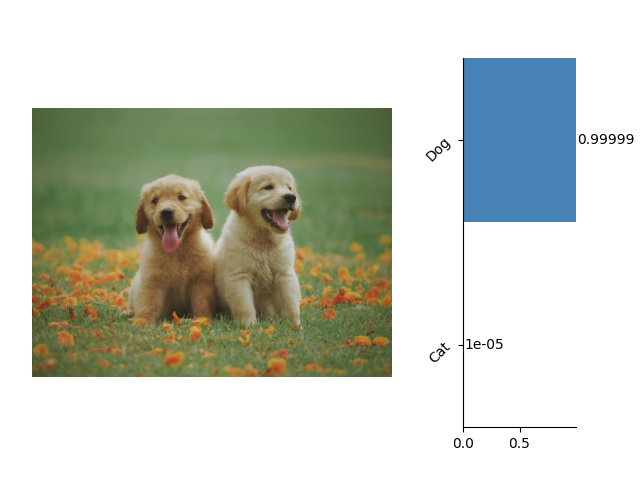
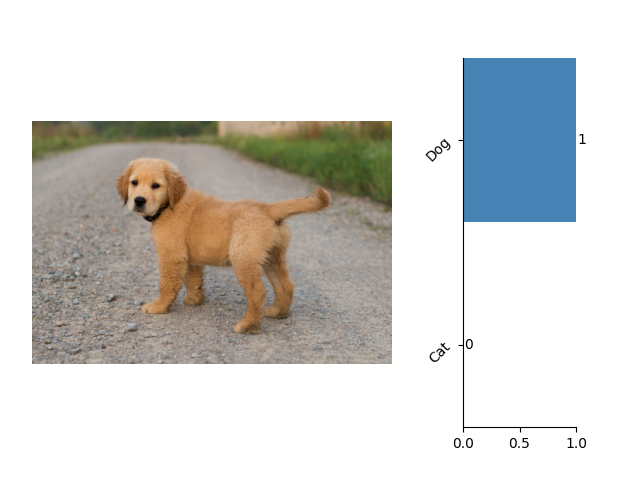
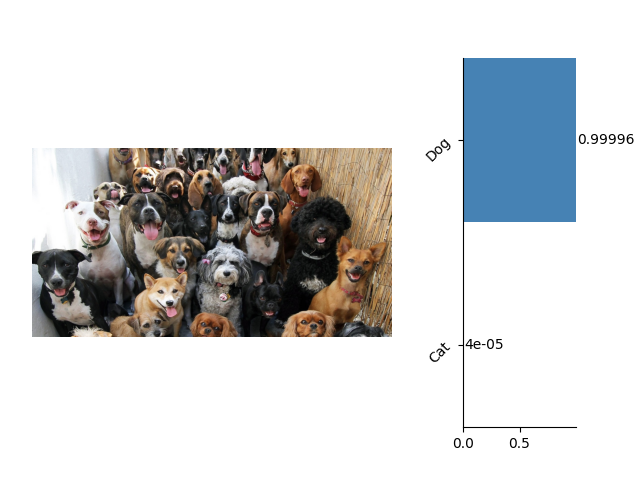
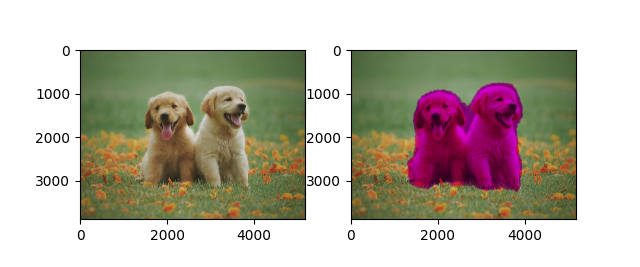
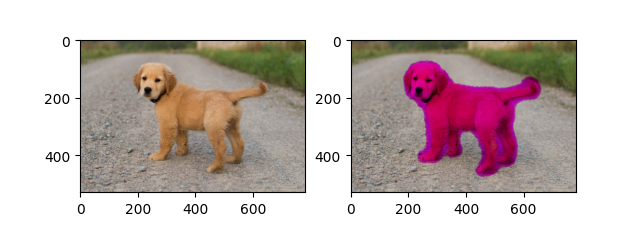
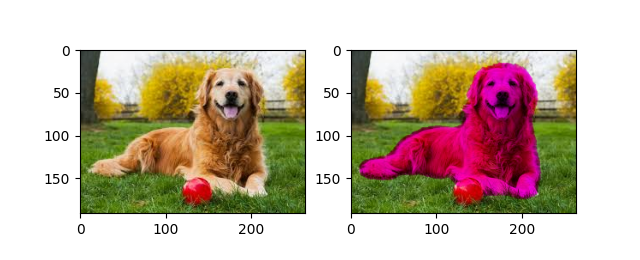
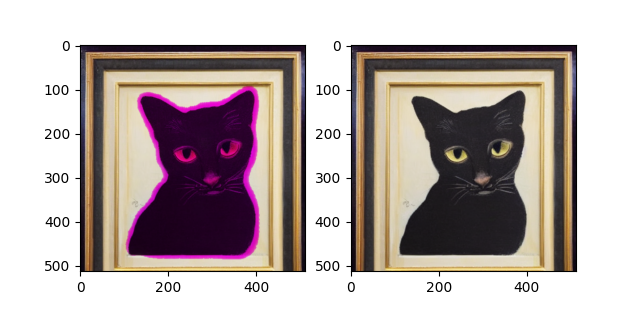
这里是一些关于语义分割的示例:
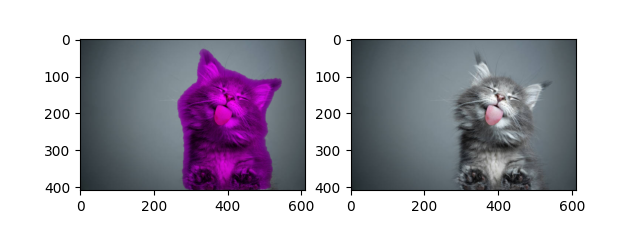

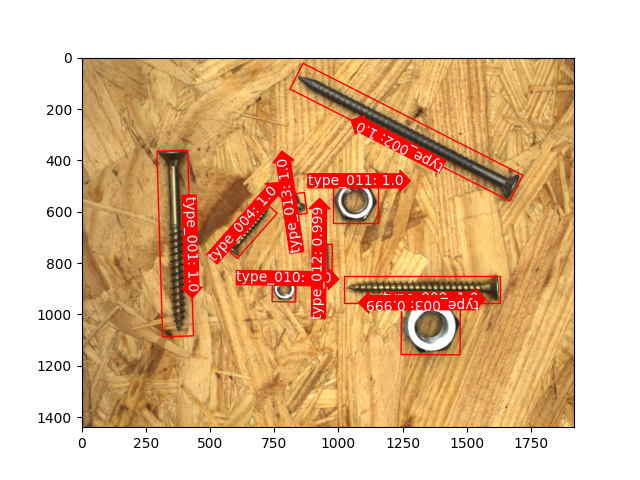
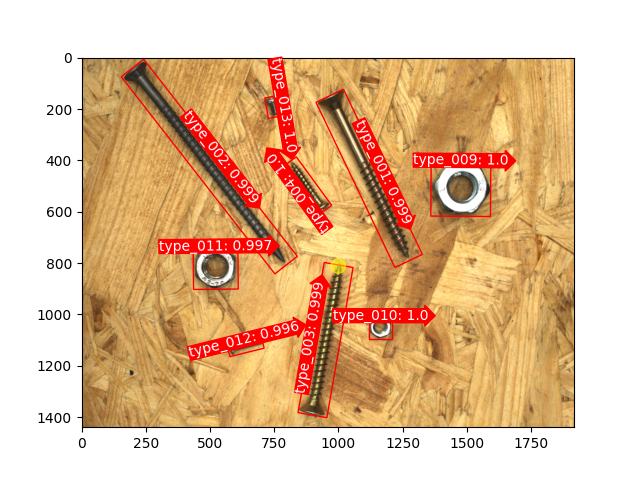
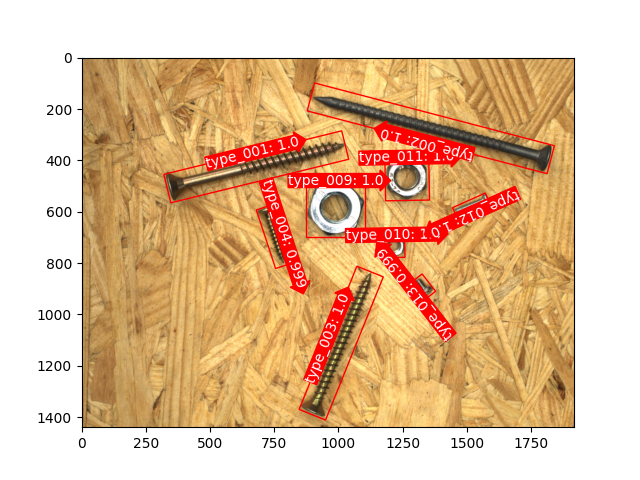
这里是一些支持方向定位的目标检测示例,该项技术基于 关键点与关节 检测技术实现。