做语音识别前常常需要先对音频文件做预编码处理,然后将处理后的数据送入模型做进一步的推理或者训练。
一般来说音频这种时讯数据可以使用傅里叶变换来取得特征,对于时长比较长的音频数据可以做短时傅里叶变换,及先将较长的时讯数据按照时长进行分段,对每一个小段单独做傅里叶变换,然后整合起来。
短时傅里叶变换仍旧有其表征上的不足,一般来说工业界倾向于使用梅尔频率倒谱系数「Mel Frequency Cepstrum Coefficient,MFCC」来做语音识别的音频预编码。
关于MFCC的具体细节可以参考资料: http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs
在Python当中可以借用librosa快速实现MFCC操作,代码示例如下:
import matplotlib.pyplot as plt
import librosa
audio_path = 'your_audio.mp3'
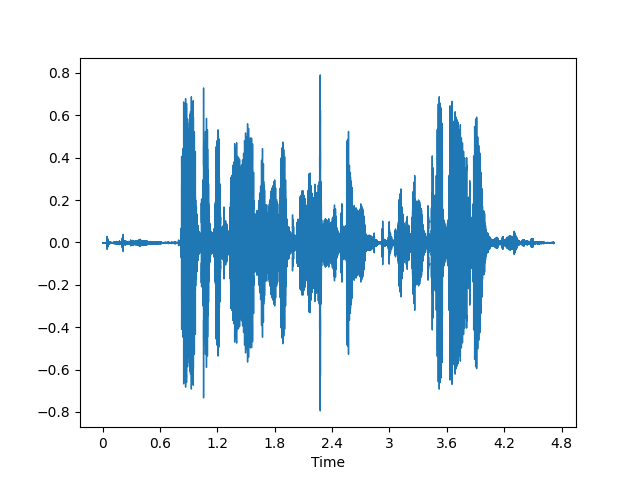
audio, sr = librosa.load(audio_path, sr=32000)
print(audio.shape, sr)
librosa.display.waveshow(audio, sr=sr)
plt.show()
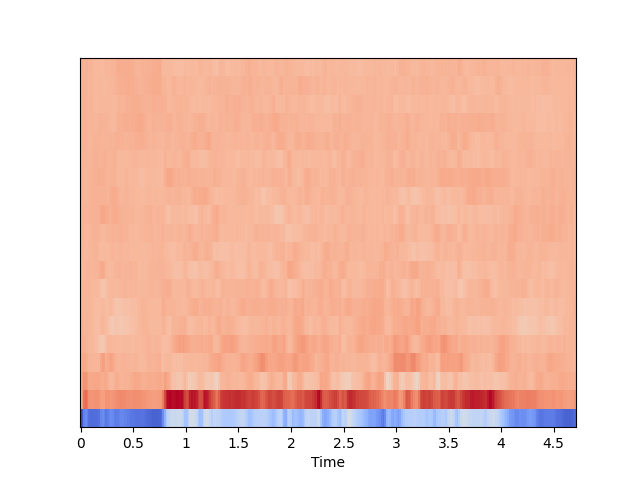
mfccs = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=20)
print(mfccs.shape, mfccs.dtype, mfccs.min(), mfccs.max())
librosa.display.specshow(mfccs, sr=sr, x_axis='time')
plt.show()
使用librosa.load可以从路径载入音频,一般来说可以指定采样率sr。librosa提供了可视化工具librosa.display.waveshow,可以帮助我们显示载入后的音频波形。
librosa.feature.mfcc可以从音频数据中提取MFCC特征,我们需要指定采样率sr,默认情况下会返回nxm的数组,n默认为20,可以使用n_mfcc参数进行指定,m对应时间轴方向。我们可以通过可视化工具librosa.display.specshow来进行观察。