今天我们使用Python编程语言和PyTorch深度学习库实现一个用于图像有损压缩的自动编码器模型,针对MNIST数据集进行讲解。
什么是自动编码器?
自动编码器是一种无监督学习算法,它可以用来学习输入数据的低维表示。自动编码器包含一个编码器和一个解码器,编码器将输入数据映射到低维空间,解码器将低维表示映射回原始空间。自动编码器的目标是通过最小化重构误差来学习这些映射,使得解码器能够生成与原始输入相似的输出。
MNIST数据集
MNIST数据集是一个手写数字数据集,包含60,000个训练样本和10,000个测试样本。每个样本是一个28x28像素的灰度图像,标签是0到9之间的数字。我们将使用MNIST数据集来训练自动编码器,以学习输入数据的低维表示。
自动编码器的实现
我们将使用PyTorch来实现自动编码器。以下是自动编码器的实现步骤:
1 .导入必要的库和数据集。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 加载MNIST数据集
train_dataset = datasets.MNIST(
root=".",
train=True,
download=True,
transform=transforms.ToTensor(),
)
test_dataset = datasets.MNIST(
root=".",
train=False,
download=True,
transform=transforms.ToTensor(),
)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=128, shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=128, shuffle=True
)
2 .定义自动编码器的结构。
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 16),
)
self.decoder = nn.Sequential(
nn.Linear(16, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 784),
nn.Sigmoid(),
)
def forward(self, x):
x = x.flatten(1)
x = self.encoder(x)
x = self.decoder(x)
return x
这个自动编码器有三个隐藏层,分别是128、64和16个神经元。编码器和解码器都使用ReLU激活函数,输出层使用Sigmoid激活函数。
3 .训练自动编码器。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Autoencoder().to(device)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 10
for epoch in range(num_epochs):
train_loss = 0
for data in train_loader:
img, _ = data
img = img.to(device)
optimizer.zero_grad()
recon = model(img)
loss = criterion(recon, img.flatten(1))
loss.backward()
optimizer.step()
train_loss += loss.item()
print("Epoch [{}/{}], Loss: {:.4f}".format(epoch + 1, num_epochs, train_loss / len(train_loader)))
torch.save(model.state_dict(), "autoencoder.pt")
我们使用BCE损失函数和Adam优化器来训练自动编码器。在每个训练周期中,我们遍历整个训练数据集,并更新模型参数。最后,我们保存训练好的自动编码器模型。
4 .测试自动编码器。
model.load_state_dict(torch.load("autoencoder.pt"))
test_loss = 0
with torch.no_grad():
for data in test_loader:
img, _ = data
img = img.to(device)
recon = model(img)
loss = criterion(recon, img)
test_loss += loss.item()
print("Test Loss: {:.4f}".format(test_loss / len(test_loader)))
在测试集上,我们计算自动编码器的重构误差。如果我们的自动编码器学习了数据的有效低维表示,那么重构误差应该比较小。
5 .使用自动编码器进行图像重构。
import matplotlib.pyplot as plt
n_images = 10
image_size = 28
fig, axes = plt.subplots(nrows=2, ncols=n_images, sharex=True, sharey=True, figsize=(20, 4))
for i in range(n_images):
test_image, _ = test_dataset[i]
test_image = test_image.to(device)
# 原始图像
axes[0][i].imshow(test_image.cpu().numpy().reshape(image_size, image_size), cmap="gray")
axes[0][i].get_xaxis().set_visible(False)
axes[0][i].get_yaxis().set_visible(False)
# 重构图像
with torch.no_grad():
outputs = model(test_image.unsqueeze(0))
reconstructed_image = outputs.cpu().numpy().reshape(image_size, image_size)
axes[1][i].imshow(reconstructed_image, cmap="gray")
axes[1][i].get_xaxis().set_visible(False)
axes[1][i].get_yaxis().set_visible(False)
plt.show()
我们可以使用训练好的自动编码器对图像进行重构。上面的代码将显示原始图像和重构图像。如果我们的自动编码器学习了数据的有效低维表示,那么重构图像应该与原始图像相似。
以下为重构效果演示,第一行为原始图像,第二行为对应的重构图像:
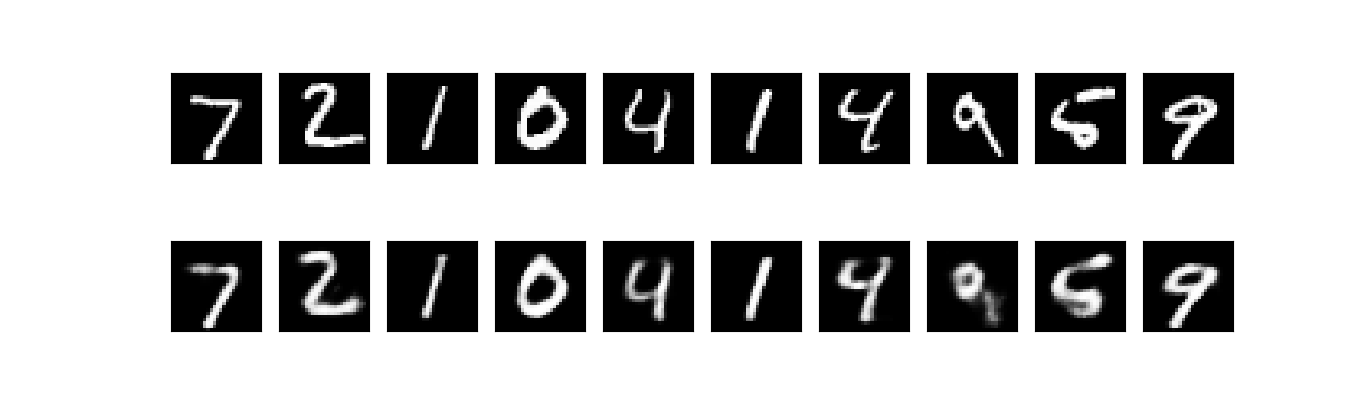
结论
在本教程中,我们使用Python和PyTorch实现了一个自动编码器,并使用MNIST数据集进行训练和测试。我们还展示了如何使用训练好的自动编码器进行图像重构。自动编码器是深度学习中的一个重要概念,