我们之前构建的神经网络都是靠普通的线性网络层Linear进行拟合,然而在处理图像数据的时候我们其实可以用效果更好的卷积网络层。将卷积网络层加入到我们的神经网络就可以在一定程度上提升模型的准确率,而由于此种神经网络的结构中包含卷积网络层,因此,也常被叫做卷积神经网络。
卷积
卷积是一种常被用在信号处理领域的计算方式,而在处理如图像这种类型的数据时常常会用到二维卷积,二维卷积的计算方式如下:
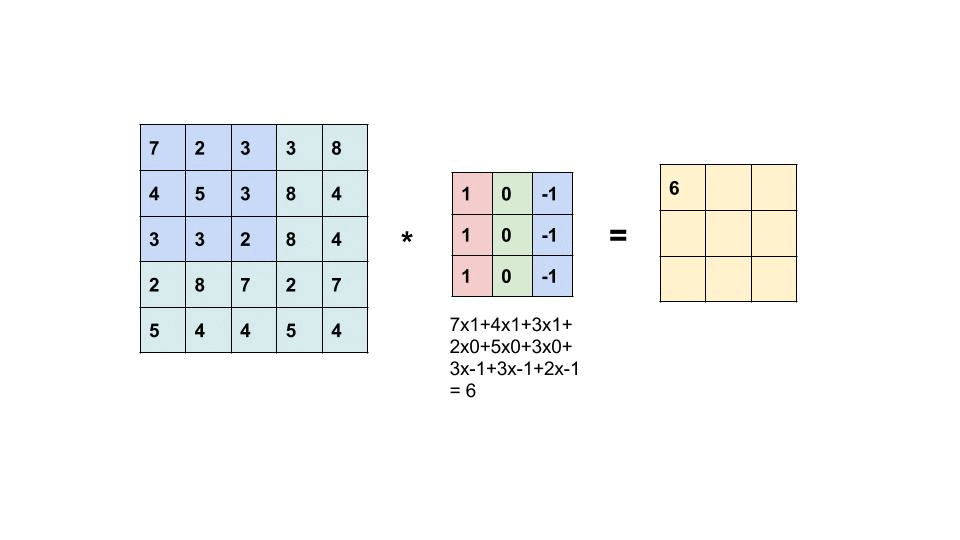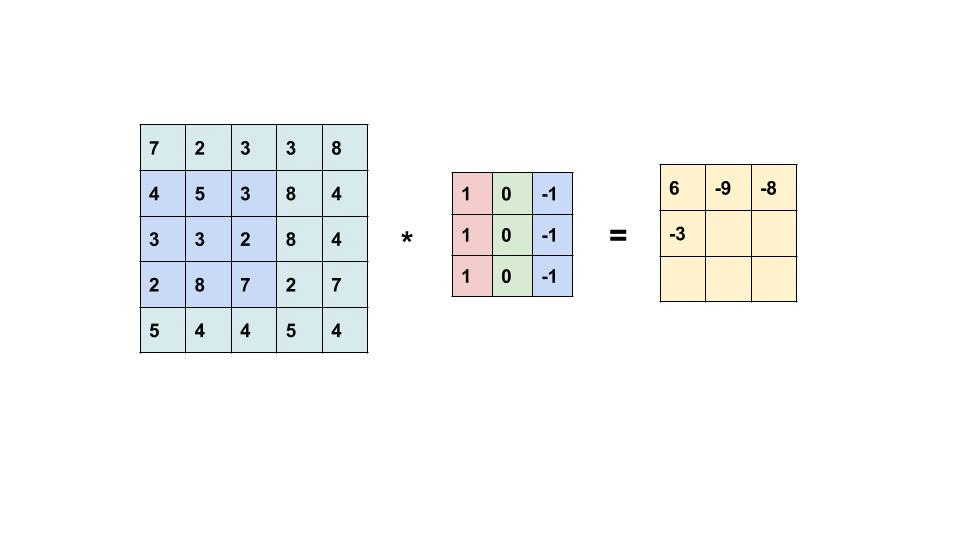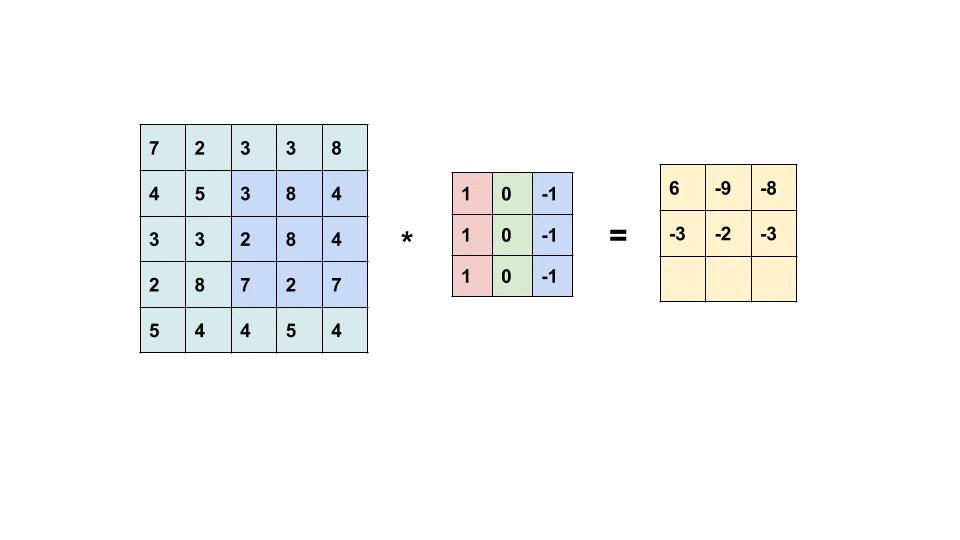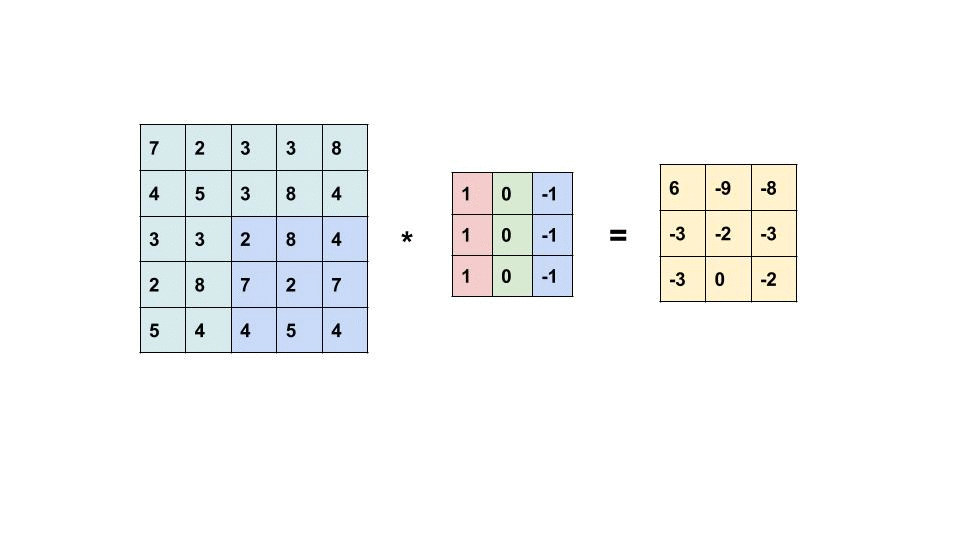
动画演示左侧的矩阵为输入,右侧的矩阵为输出,中间的是卷积核,卷积核的概念类似线性计算中的权重Weight,我们可以将卷积操作写成如下公式:
$$ Y = X \ast k $$
假设输入X是一个5x5的矩阵,而卷积核k是一个3x3的矩阵,那么输出的Y是一个$(5 - 3 + 1)$x$(5 - 3 + 1)$的矩阵及3x3的矩阵。计算方法是: 输出Y的维度 = 输入X的维度 - 卷积核k的维度 + 1。
池化
池化操作常常与卷积操作一同使用,它可以让数据变得「精炼」:
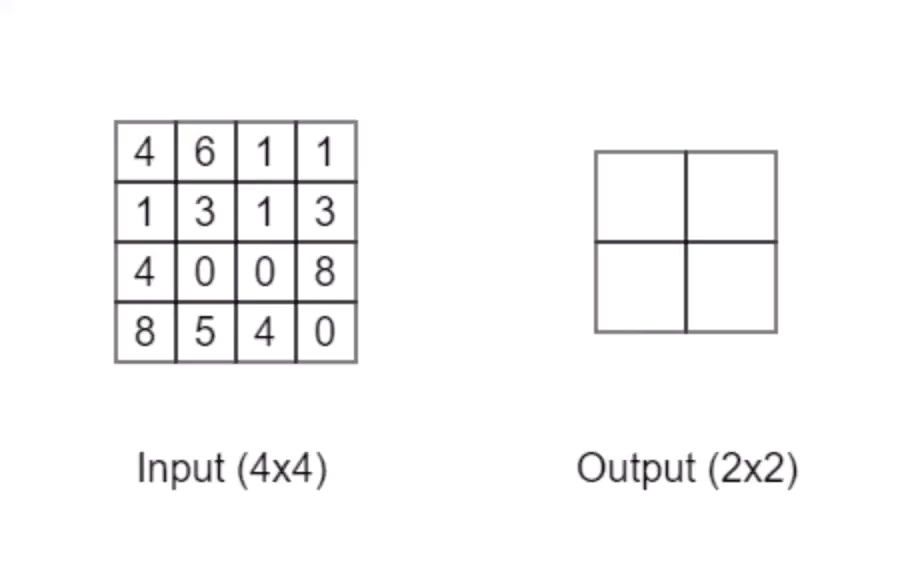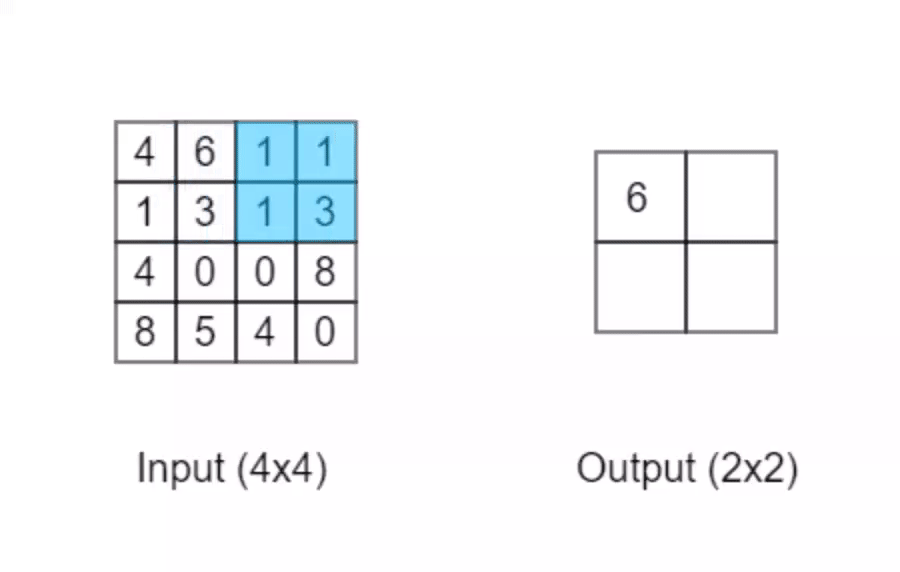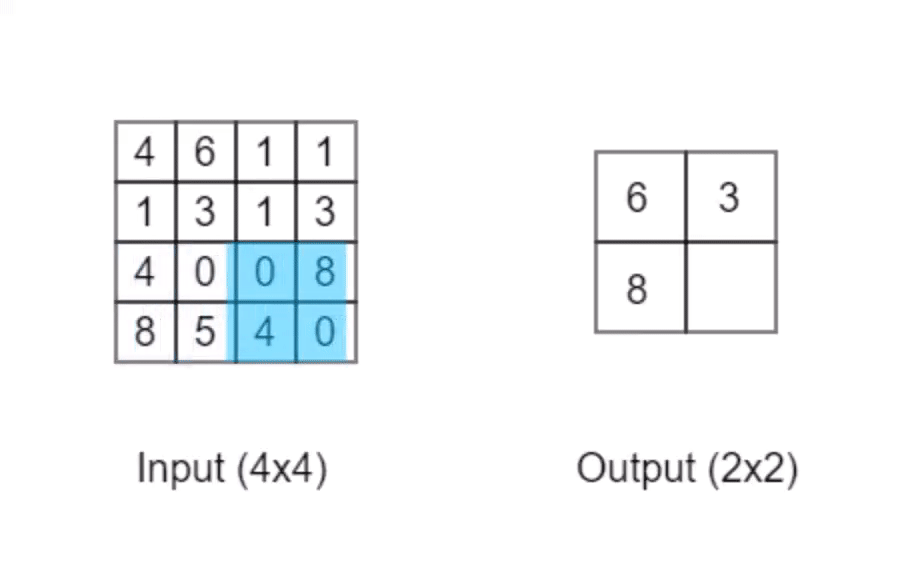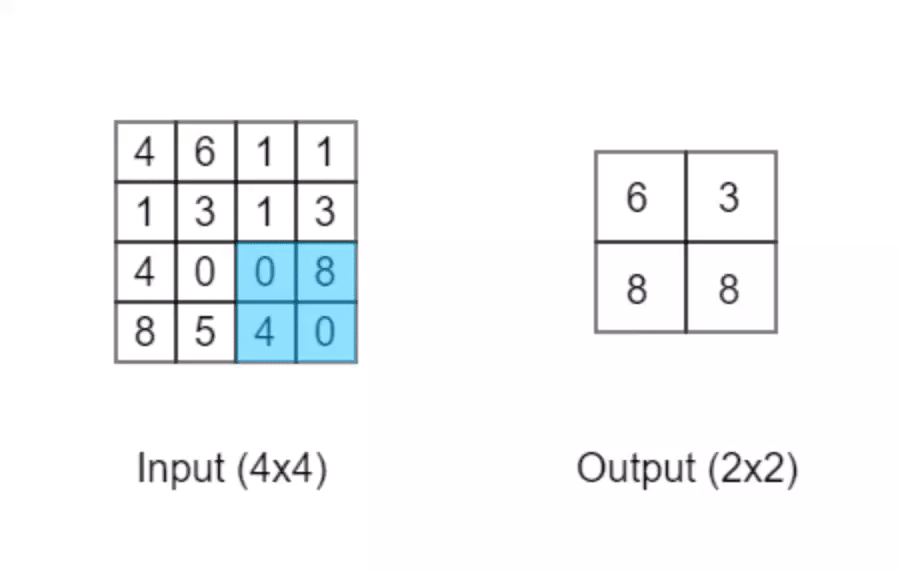
以上动画演示的是最大池化操作,它会输出数个相邻格子中最大的值。当它的检测窗口大小为2x2时「正如动画中所示」,它可以将原本输入的4x4的矩阵转变为2x2的矩阵输出。
了解了卷积和池化操作,我们再来看看如何应用到神经网络。
卷积神经网络
上一节中,我们的神经网络结构如下:
mlp = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 256),
nn.ReLU(inplace=True),
nn.Linear(256, 10),
nn.Softmax(dim=1))
我们将其进行修改:
cnn = nn.Sequential(
nn.Conv2d(1, 10, 5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Conv2d(10, 20, 3),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(20 * 5 * 5, 10),
nn.Softmax(dim=1))
调用nn.Conv2d(1, 10, 5)构建一个卷积层,它的输入为1,对应图像的通道数,输出通道数为10,卷积核的大小为5x5;调用nn.MaxPool2d(2)构建一个最大池化层,它的检测窗口大小为2x2……
- 我们输入数据的维度是: nx1x28x28「batch size x 图像通道数 x 图像像素高度 x 图像像素宽度;
- 经过神经网络第一层
nn.Conv2d(1, 10, 5)输出: nx10x24x24; - 经过神经网络第二层
nn.ReLU(inplace=True)输出: 同上; - 经过神经网络第三层
nn.MaxPool2d(2)输出: nx10x12x12; - 经过神经网络第四层
nn.Conv2d(10, 20, 3)输出: nx20x10x10; - 经过神经网络第五层
nn.ReLU(inplace=True)输出: 同上; - 经过神经网络第六层
nn.MaxPool2d(2)输出: nx20x5x5; - ……
重新运行代码训练模型
我们在同之前一样的条件下训练这个卷积神经网络。
通过10轮的训练,我们的新模型在测试集上的表现如下:
testing...
loss=1.4784890896157374, accuracy=0.9838
其中损失率loss为1.478489左右,准确率达到98.38%。
这一次修改使得模型无论在拟合效果还是最终测试准确率上都有显著提升。
完整代码
import torch
torch.manual_seed(3)
import torch.nn as nn
import torch.nn.functional as F
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
train_set = MNIST('.', train=True, download=False, transform=ToTensor())
test_set = MNIST('.', train=False, download=False, transform=ToTensor())
train_loader = DataLoader(train_set, batch_size=128, shuffle=True)
test_loader = DataLoader(test_set, batch_size=128, shuffle=False)
cnn = nn.Sequential(
nn.Conv2d(1, 10, 5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Conv2d(10, 20, 3),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(20 * 5 * 5, 10),
nn.Softmax(dim=1))
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.001)
for epoch in range(10):
print('training...')
cnn = cnn.train()
for step, (inputs, targets) in enumerate(train_loader):
outputs = cnn(inputs)
loss = F.cross_entropy(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 100 == 0:
with torch.no_grad():
compares = torch.argmax(outputs, dim=1) == targets
accuracy = torch.mean(compares.type(torch.float32)).item()
print(f'{epoch}:{step}, loss={loss.item()}, accuracy={accuracy}')
print('testing...')
cnn = cnn.eval()
losses = []
count = 0
with torch.no_grad():
for step, (inputs, targets) in enumerate(test_loader):
outputs = cnn(inputs)
loss = F.cross_entropy(outputs, targets)
losses.append(loss.item())
compares = torch.argmax(outputs, dim=1) == targets
count += torch.sum(compares.type(torch.long)).item()
loss = sum(losses) / len(losses)
accuracy = count / len(test_set)
print(f'loss={loss}, accuracy={accuracy}')
torch.save(cnn, 'cnn.pt')
cnn = torch.load('cnn.pt')
print(cnn)