先前我们在最小二乘拟合那一节中了解到如何使用最小二乘的方法拟合多项式方程,那么今天我们再来学习一种「拟合」方程的方法——逻辑回归。
我们要处理的问题是这样的:
需要一个方程能够检测两位的二进制数字「包括 00 01 10 11」是否为奇数,当输入为奇数时方程输出1,输入为偶数时方程输出0。
上述方程接收输入并输出类似逻辑电路中高低电平信号的0,1值,很容易让人联想到使用逻辑回归方法去求解。因此,接下来我们就尝试使用逻辑回归进行求解。
定义函数
我们的方程表达式如下:
$$ y = \sigma(XW + b) $$
其中X为方程输入,y为方程输出。W与b为方程的参数,具体数值需要经过拟合求得。
方程的输入X为二进制数转换成的矩阵,二进制数与矩阵的对应关系如下:
$$ \begin{align} 00 \rightarrow \begin{bmatrix} 0 & 0 \end{bmatrix} \\ 01 \rightarrow \begin{bmatrix} 0 & 1 \end{bmatrix} \\ 10 \rightarrow \begin{bmatrix} 1 & 0 \end{bmatrix} \\ 11 \rightarrow \begin{bmatrix} 1 & 1 \end{bmatrix} \\ \end{align} $$
参数W是个2x1的矩阵: $W = \begin{bmatrix}w_1 \\ w_2 \end{bmatrix}$;参数b则为一个标量。
函数$\sigma(x)$为著名的sigmoid函数:
$$\sigma(x) = \frac{1}{1 + e^{-x}}$$
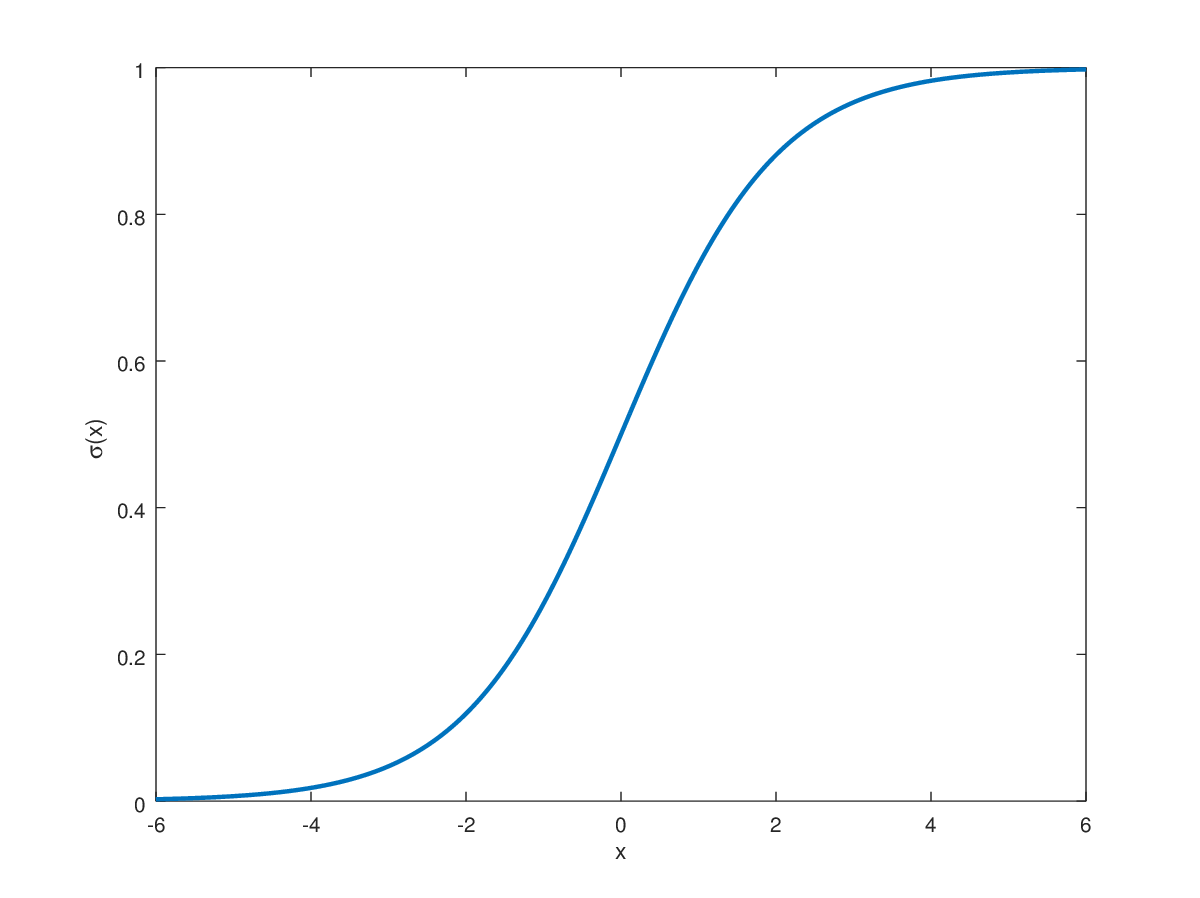
从函数图可以看出该函数的输出会落在0与1之间,并且在输入大于0的时候函数输出会快速趋近1,输入小于0的时候函数输出则会快速趋近0。
优化学习
为了求解具体的参数数值,我们可以先预设参数,然后对参数进行优化更新,使其变成符合我们期望的参数。
在对参数进行优化前,我们还得设计一个方案去评估参数的效果,如果不知道当前参数的效果我们是无法顺利地对参数进行优化的。
一般来说逻辑回归可以使用 梯度下降算法 进行参数优化,而该算法应用在逻辑回归时也有常用的参数评估函数「或称 损失函数」:
$$ loss = \sum_{i=1}^n\frac{1}{2}(t_i - p_i)^2 $$
在上述方程中$t_i$为第i个真实输出「或者说是预期中的函数输出」,而$p_i$则是与之对应的当前函数给出的输出。
假设X为输入,期望中的函数为$f_t$,当前函数为$f_p$,那么t与p的对应关系大致如下:
$$ \begin{pmatrix} t_1 \leftrightarrow p_1 \\ t_2 \leftrightarrow p_2 \\ t_3 \leftrightarrow p_3 \\ t_4 \leftrightarrow p_4 \\ \end{pmatrix} \left\{ \begin{align} \begin{bmatrix} t_1 \\ t_2 \\ t_3 \\ t_4 \end{bmatrix} = T & = f_t(X) \\ \begin{bmatrix} p_1 \\ p_2 \\ p_3 \\ p_4 \end{bmatrix} = P & = f_p(X) \\ \end{align} \right. \quad , \quad X = \begin{bmatrix} 0 & 0 \\ 0 & 1 \\ 1 & 0 \\ 1 & 1 \end{bmatrix} $$
在计算完损失函数值后,我们就对损失函数求参数$\{W,b\}$的梯度$\{\Delta W,\Delta b\}$,然后用当前的参数分别减去各自的梯度用以得到更新后的参数:
$$ W_t = W_{t-1} - \lambda \Delta W \ ; \ b_t = b_{t-1} - \lambda \Delta b $$
通常在使用梯度进行参数更新的时候我们不希望使用全部的梯度,这样会使得数值跨度太大,因此我们通常会将梯度乘上一个小于1的正数$\lambda$,很多地方称$\lambda$为学习率「learning rate」。
了解了这些后我们开始编写代码。
准备输入输出
在确保安装了pytorch后我们在代码中引入它:
import torch
torch.tensor类似numpy中的numpy.array,我们可以使用它创建张量「包括标量,向量,矩阵……」。在这里,我们使用张量存储方程的输入X与输出T。X为4x2的矩阵而T为4x1的矩阵,它们的每一行按顺序互相对应:
X = torch.tensor([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
], dtype=torch.float32)
T = torch.tensor([
[0],
[1],
[0],
[1]
], dtype=torch.float32)
这里需要注意的是我们大多数情况会使用32位的浮点数值torch.float32,这样做既能满足精度的需要又避免过多的运算。
准备需要拟合的参数
公式 $y = \sigma(XW + b)$ 中的W「常常称作权重Weights」与b「常常称作偏置bias」是我们需要拟合的参数:
W = torch.ones((2, 1), dtype=torch.float32, requires_grad=True)
b = torch.zeros((1, ), dtype=torch.float32, requires_grad=True)
我们将权重初始化为元素都是1的矩阵,而偏置则初始化为0。另外,由于我们需要求解权重和偏置的梯度,所以我们需要设置参数requires_grad=True。
正向传播
我们在一个for循环中编写正向传播的代码:
for step in range(100):
# forward
A = X @ W
H = A + b
P = torch.sigmoid(H)
代码是根据公式 $y = \sigma(XW + b)$ 编写的,经由sigmoid函数处理后的输出P就对应公式中的输出y。
计算损失函数
我们根据如下公式编写损失函数:
$$ loss = \sum_{i=1}^n\frac{1}{2}(t_i - p_i)^2 $$
loss = torch.sum(0.5 * (T - P)**2)
print('step:', step, 'loss =', loss.item())
反向传播
调用loss.backward方法,对支持梯度求解的张量对象loss进行梯度求解:
# backward
loss.backward()
在执行完反向传播操作后,我们可以得到权重的梯度W.grad以及偏置的梯度b.grad。
更新梯度
由于我们使用的是梯度下降优化方案所以在更新权重和偏置的时候需要减去梯度。但是如果直接减去梯度则可能步长过大,所以通常会将梯度乘上一个小于1大于0的值lr,然后用当前权重减去它,正如下方那样:
lr = 0.1
with torch.no_grad():
W -= W.grad * lr
b -= b.grad * lr
W.grad.data.zero_()
b.grad.data.zero_()
在pytorch中,更新带有梯度的参数时,我们需要在不计算梯度的模式下with torch.no_grad():进行;而在更新梯度后,我们需要使用tensor.grad.data.zero_()方法清零当前的梯度。
查看拟合后的参数
完成100轮上述的权重与偏置的更新后我们打印输出一下权重和偏置:
print('params weight:')
print(W.detach())
print('params bias:')
print(b.detach())
tensor.detach()方法用于将普通tensor从带梯度的tensor中分离,此处使用仅为了打印输出的美观。
测试拟合效果
我们在不计算梯度的模式下测试一下拟合后的方程。在这里我们使用pytorch张量对象的列表索引X[[0, 2, 1, 3]]改变了一下矩阵X的行顺序,那么对应的输出P则应该趋近于$\begin{bmatrix}0 \\ 0 \\ 1 \\ 1\end{bmatrix}$:
with torch.no_grad():
A = X[[0, 2, 1, 3]] @ W
H = A + b
P = torch.sigmoid(H)
print('predict:')
print(P)
运行后输出:
predict:
tensor([[0.2789],
[0.3257],
[0.7348],
[0.7759]])
我们发现输出的头两行元素小于0.5趋近0,后两行元素大于0.5趋近1,基本符合我们的预期,这时我们可以使用torch.round进行四舍五入将其严格转换为$\begin{bmatrix}0 \\ 0 \\ 1 \\ 1\end{bmatrix}$的结构:
print(torch.round(P))
运行后输出:
tensor([[0.],
[0.],
[1.],
[1.]])
完整代码
import torch
X = torch.tensor([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
], dtype=torch.float32)
T = torch.tensor([
[0],
[1],
[0],
[1]
], dtype=torch.float32)
W = torch.ones((2, 1), dtype=torch.float32, requires_grad=True)
b = torch.zeros((1, ), dtype=torch.float32, requires_grad=True)
for step in range(100):
# forward
A = X @ W
H = A + b
P = torch.sigmoid(H)
loss = torch.sum(0.5 * (T - P)**2)
print('step:', step, 'loss =', loss.item())
# backward
loss.backward()
lr = 0.1
with torch.no_grad():
W -= W.grad * lr
b -= b.grad * lr
W.grad.data.zero_()
b.grad.data.zero_()
print('params weight:')
print(W.detach())
print('params bias:')
print(b.detach())
with torch.no_grad():
A = X[[0, 2, 1, 3]] @ W
H = A + b
P = torch.sigmoid(H)
print('predict:')
print(P)
print(torch.round(P))