上一节中介绍了最小二乘法,本节将介绍另一个数据分析方法——聚类分析。该方法常用于处理具备几何特征关系的数据点,我们以最基础的k均值聚类为例进行说明。
k均值聚类「kmeans」
k均值聚类通俗来说就是将n个数据点按照一定规则分配到k个族群,要求每个数据点距离所在族群的均值点比较近而距离其它族群的均值点比较远。
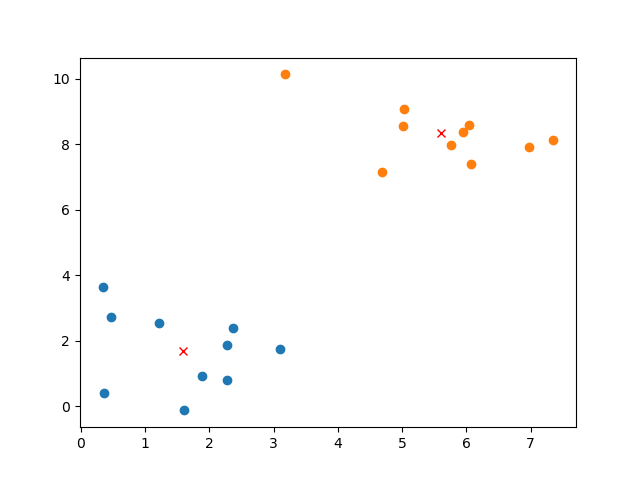
如上图,有两个颜色不同的族群,这两个族群的均值点都用红色的x进行了标记。可以看出各个族群的点都是距离自己族群的均值点比较近而距离其它族群的均值点比较远。
k均值算法步骤
注意: 这里给出的是k均值聚类的一种实现方案,如果你在其它地方看到其它方法请不要觉得奇怪。
- 从样本点中随机选出k个样本点作为k个均值点,而每个均值点拥有一个对应的族群;
- 将均值点以外的其它样本点与这k个均值点做距离评估,将样本点分配给距离较近的均值点所对应的族群;
- 为每个族群重新计算一个均值点;
- 重复「步骤2」到「步骤3」的过程,直到累计重复了某个次数或者各个均值点变更的幅度减小到了某个程度;
代码实现・数据准备
首先我们构造一下数据点:
import matplotlib.pyplot as plt
import numpy as np
pts = np.random.randn(20, 2)
pts[:10] += [0.5, 1]
pts[10:] += [5, 10]
我们随机初始了20个标准正态分布的二维座标点pts,然后将前10个点和后10个点的座标分别加上$(0.5, 1)$,$(5, 10)$使这两组数据点的均值分别趋近于$(0.5, 1)$,$(5, 10)$「当然,我们并不会把均值点调整的这个信息告诉后面的k均值算法」。
我们用numpy.random.permutation生成一个随机索引序列用来打乱原本pts中的顺序,算是给实验增加一点点挑战:
idx = np.random.permutation(len(pts))
pts = pts[idx]
代码实现・步骤一
def kmeans_step1(k=2):
centroids = pts[np.random.choice(len(pts), k, replace=False)]
return centroids
使用numpy.random.choice生成k个不重复的索引下标,参数设定replace=False确保不重复。
代码实现・步骤二
def kmeans_step2(centroids):
clusters = {i: [] for i in range(len(centroids))}
for point in pts:
c_id = np.argmin(np.sum((centroids - point)**2, axis=1))
clusters[c_id].append(point)
return clusters
我们使用迭代的方法遍历每一个点,用各个点同均值点centroids做欧氏几何距离评估来判断当前点point属于哪一个族群cluster。
欧氏几何距离计算的公式为 $d(p,q) = \sqrt{\sum_{i=1}^{n} (p_i - q_i)^2}$,由于我们只需要获取极小值所以不必计算最外层的开方,于是有 $\hat{d}(p,q) = \sum_{i=1}^{n} (p_i - q_i)^2$,代码的表现形式如下:
c_id = np.argmin(np.sum((centroids - point)**2, axis=1))
函数numpy.argmin取出数组最小值所在的下标。
代码实现・步骤三
def kmeans_step3(clusters):
centroids = np.zeros((len(clusters), 2))
for i, c_pts in clusters.items():
centroids[i] = sum(c_pts) / len(c_pts)
return centroids
在步骤三的函数中我们将每一个族群的数据点相加然后除以族群中数据点的数目,这样得到的均值会作为新的均值点。
代码实现・算法总成
最后,我们来看一下所有步骤的执行过程:
# 步骤一
k = 2
centroids = kmeans_step1(k)
print(centroids)
# 重复3次「步骤二,步骤三」
for i in range(3):
# 步骤二
clusters = kmeans_step2(centroids)
# 步骤三
centroids = kmeans_step3(clusters)
print(centroids)
如果愿意我们也可以绘制出最终的结果:
plt.plot(pts[:, 0], pts[:, 1], 'o', centroids[:, 0], centroids[:, 1], 'x')
plt.show()