我们学习了如何使用Python访问网络上的HTTP资源,下面我们将使用一个叫煎蛋的网站来入手学习Web爬虫技术。
目标介绍
我们需要使用Python获取煎蛋网中的宠物图像资源,实现批量下载宠物图像的功能。
graph TB
Site[煎蛋网 jandan.net/zoo] -- HTTP请求 --> Page[网页 HTML]
Page -- 字符串查找 --> Images[图像连接 URL]
Images -- HTTP请求 --> Storage[本地图像 JPG/PNG/...]
网页元素查找
我们可以使用浏览器自带的Web开发辅助工具来辅助爬虫项目的开发:
- 在网页 https://jandan.net/zoo 页面右键点击元素审查「或者输入快捷键
Ctr+Shift+I」开启辅助工具; - 点击挑选页面元素的工具「或者输入快捷键
Ctr+Shift+C」; - 尝试点击页面中的图像然后观察元素面板的变化,就可以找到对应的图像资源;
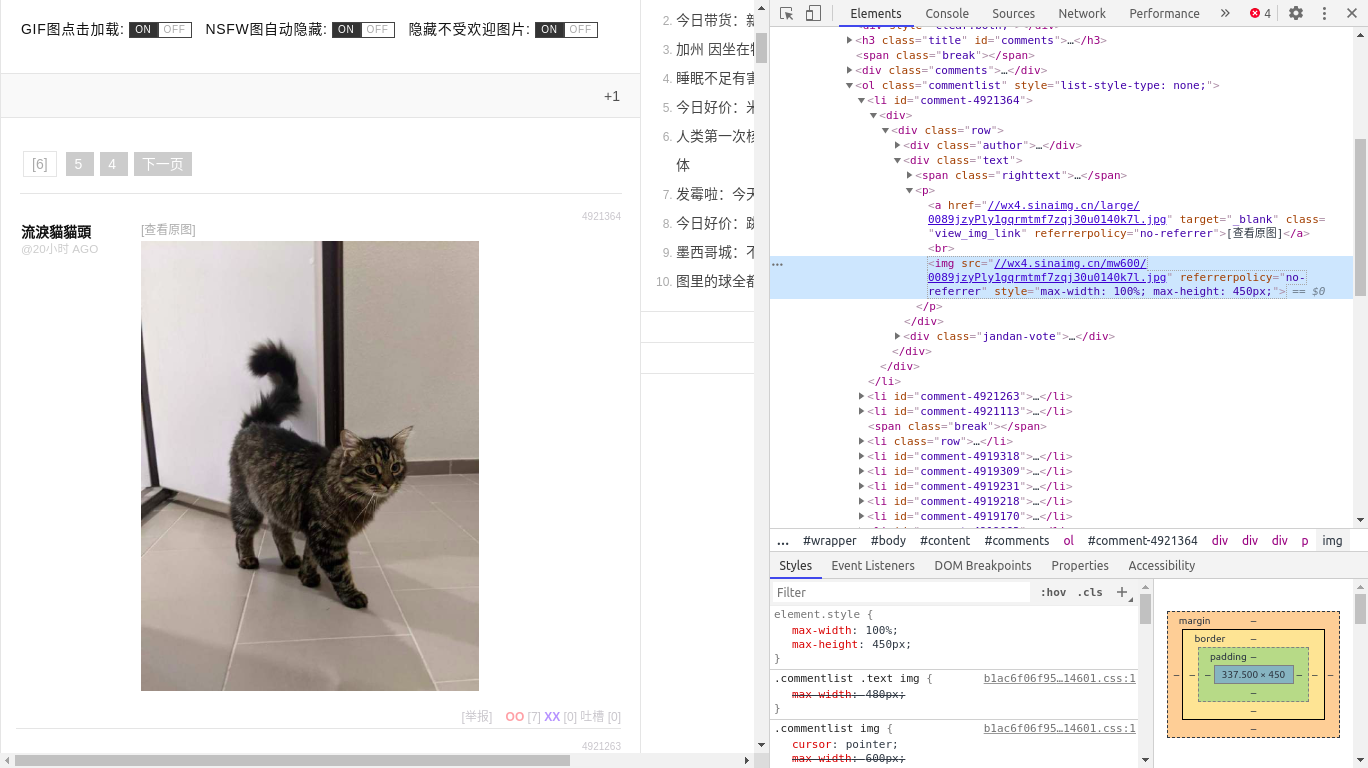
经过反复的测试,我们得知大概有两种形式「如果考虑gif格式可能会更复杂」的目标图像:
- 原图图像链接的格式 //wx4.sinaimg.cn/large/xxx.xxx
- 展示图像链接的格式 //wx4.sinaimg.cn/mw600/xxx.xxx
获取网页页面
使用urllib访问该网站时注意要自定义headers中的User-Agent项:
from urllib.request import Request, urlopen
url = 'https://jandan.net/zoo'
headers = {'User-Agent': 'Chrome hkw 031 web'}
request = Request(url, headers=headers)
html = urlopen(request).read().decode()
搜索原图链接
使用正则表达式匹配查询原图链接:
import re
pattern = re.compile(r'//wx4.sinaimg.cn/large/[^"]+')
links = re.findall(pattern, html)
批量下载图像
遍历links并构建Request对象请求图像资源:
for i, link in enumerate(links):
request = Request(f'https:{link}', headers=headers)
ext = link.split('.')[-1]
data = urlopen(request).read()
with open(f'{i}.{ext}', 'wb') as f:
f.write(data)
print(i, link)