上一节中我们编译运行了一段NASM汇编代码,接下来我们将针对上一节的代码进行解析,了解一些具体的汇编知识。
程序结构
我们先将上一节中的代码通过调整变成如下形式:
global _start
section .text
_start: mov rax, 1
mov rdi, 1
mov rsi, message
mov rdx, 13
syscall
mov rax, 60
xor rdi, rdi
syscall
section .data
message: db "Hello, World", 10
然后再整理成表格形式:
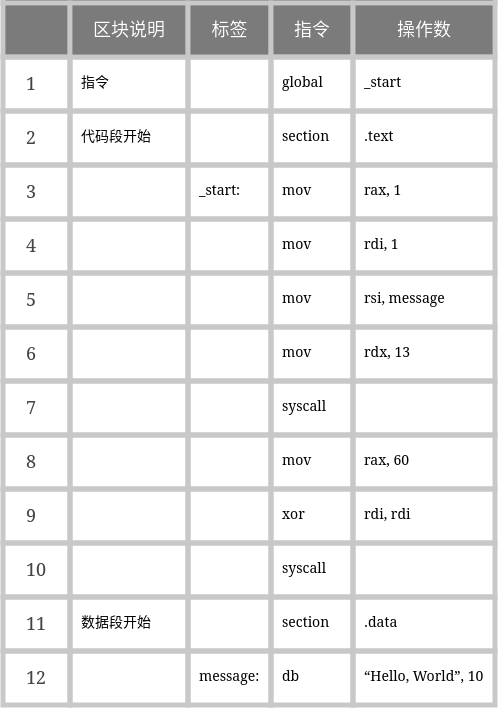
主程序中需要指定代码从哪里开始运行,做法是设置_start标签并使用global将其暴露给汇编器;程序由指令和段组成,常见的段有代码段.text、数据段.data;指令语句主要由指令或指令+操作数组成,例如:mov rax, 1。
通常我们会在代码段声明语句section .text后接上入口标签_start:并开始编写一系列的指令操作;对于数据段声明语句section .data,我们会在其后接上声明的数据以及对应的标签。
操作指令
NASM的操作指令非常多,但是我们并不需要全部掌握,以下列举最常见的指令:
mov x, y将y的值给到x;and x, y将x、y进行与运算,把结果给到x;or x, y将x、y进行或运算,把结果给到x;xor x, y将x、y进行亦或运算,把结果给到x;add x, y将y累加到x;sub x, y从x中减去y;inc x让x自增1;dec x让x自减1;
寄存器
寄存器主要用于存取数值,可以被当作高级程序语言中的数值变量来使用。
当我们想进行64位数值操作的时候,我们常会使用英文字母r开头的寄存器,可以初步理解为64位的整型变量:
- RAX
- RCX
- RDX
- RBX
- RSP
- RBP
- RSI
- RDI
当我们想进行32位数值操作的时候,我们常使用英文字母e开头的寄存器,可以初步理解为32位的整型变量:
- EAX
- ECX
- EDX
- EBX
- ESP
- EBP
- ESI
- EDI
把64位寄存器的首字母r去掉,或者把32位寄存器的首字母e去掉则变为16位的寄存器,可以理解为16位的整型变量:
- AX
- CX
- DX
- BX
- SP
- BP
- SI
- DI
可以将16位的寄存器拆分为两个8位的寄存器,高位的部分称作高8位寄存器,低位的部分称作低8位寄存器。
常见低8位寄存器:
- AL
- CL
- DL
- BL
- SPL
- BPL
- SIL
- DIL
常见高8位寄存器:
- AH
- CH
- DH
- BH
下面,我们类比C语言,使用NASM代码来实现对应的操作。
有C语言如下:
char c;
c = 'a';
变换成NASM:
mov al, 'a'
有C语言如下:
c += 1;
变换成NASM:
add al, 1
内存寻址
由于寄存器数量有限,在处理较为复杂的数据结构时,我们需要利用内存来完成数据存取。
在汇编中,我们可以指定一段内存地址,然后写入或者读取一段数据。通过汇编语言的寻址操作,我们可以得到目标地址:
[数字][寄存器][寄存器 + 数字][寄存器 + 寄存器*scale]scale 可以是 1, 2, 4, 8[寄存器 + 寄存器*scale + 数字]
数字指的是偏移量,普通的寄存器被称作基址寄存器,寄存器*scale被称作索引。
示例:
[123]偏移[rbp]基址[rbx - 8]基址 + 偏移量 -8「反向偏移8个单位」[rcx + rsi*4]基址 + 索引*scale[rbp + rdx]scale为1可以省略[rax + rdi*8 + 500]完整的写法[rbx + message]可以使用标签作为偏移量,这使得标签具备变量名的作用
立即数操作
在代码中我们可以直接使用数值,例如: 10进位的100;16进位的0xff;2进位的0b11……,有个好消息是我们仍旧可以使用字符「编译器会转换为ascii对应的数字,本质上也是数字的一种写法」。
下面我们修改之前的代码,使用寻址操作将输出字符串Hello, World变为小写的hello, world,我们仅需要通过寻址修改两个字符:
global _start
section .text
_start:
; 将偏移量交给rax
mov rax, message
; 给rax所在的地址赋值'h',需要声明是在字节范围进行的操作
mov byte [rax], 'h'
; 给rax+7所在的地址赋值'w',需要声明是在字节范围进行的操作
mov byte [rax + 7], 'w'
mov rax, 1
mov rdi, 1
mov rsi, message
mov rdx, 13
syscall
mov rax, 60
xor rdi, rdi
syscall
section .data
message:
db "Hello, World", 10
系统调用
在C语言中我们常使用printf函数打印字符串,然而这个函数并不是由我们自己完成,一般来说系统库会为我们提供他。在汇编当中我们也可以使用类似的由系统提供的工具,在64位的NASM中称其为系统调用syscall。
在我们的示例代码中有两次使用了系统调用。
第一次是打印输出字符串:
mov rax, 1
mov rdi, 1
mov rsi, message
mov rdx, 13
syscall
syscall前的寄存器操作是在设定我们以何种方式进行系统调用。rax的值决定使用哪一个系统调用,1对应的就是写入操作;此时rdi设置为1表示标准输出;rsi则存放字符串地址;rdx记录字符串长度。
第二次是结束程序,相当于exit(0):
mov rax, 60
xor rdi, rdi
syscall
当rax的值为60时表示调用退出操作;此时rdi为0表示以0号状态进行退出,就像C语言中exit(0);。
定义或声明数据
我们将数据的定义或声明放在数据段中,它的形式是这样: 标签: 类型 值。
db用于定义字节byte,例如:
message:
db 'H', 'e', 'l', 'l', 'o', ' ', "World", 10 ;
dw用于定义字word,例如:
number_dw:
dw 1, 2, 3
dd用于定义双字double word,例如:
number_dd:
dd 1, 2, 3